


Online communication has moved in an alarming direction, with a huge 59% of teens in the US and 55% of people aged 17–24 in Britain having experienced cyberbullying. In Finland, nearly half of all children face harassment online. In many cases, people are the victim of a crime but don’t even realize this is the case – and if they do realize, they don’t know how to find out what they can do about it.
That’s where SomeBuddy can help. SomeBuddy is a legal startup whose goal is to lower the threshold for social media users, especially younger ones, to seek help – quickly and scalably.
The problem of expanding across languages
SomeBuddy is a web app where users can report cyberbullying or harassment online and receive a tailor-made response including legal advice and psychological first-aid. With the help of professional lawyers and psychologists, as well as machine learning-based tools, SomeBuddy helps victims to learn more about unpleasant situations on social media and how to get help.
To be able to provide the service for all social media users, Somebuddy’s idea from the beginning has been to create tools that assist their lawyers and psychologists by automating as much of the work as possible. SomeBuddy’s “crime detector” is one of these tools, which uses natural language processing (NLP) to predict crime labels such as “defamation” or “child sexual abuse” from input given by a user. The service team will get suggestions as to what a given crime label might be based on the predictions of the model.
When it was time to expand to Sweden, SomeBuddy needed to seek a solution on how to utilize their existing model in a new market but there was a challenge – the crime detector had been trained with Finnish language data and as such it could not be applied to incoming cases in Swedish. To solve this problem, Reaktor and SomeBuddy teamed up to explore the possibilities.
Why translation was not an option
The most obvious approach would have been to translate all the data into Swedish, by human or by machine, and train a new Swedish model based on that. The problem with this approach is that it is not scalable when thinking about further expansion: even with two individual language models you would need to keep translating messages from one language to another in order to keep adding predictive power to the models. This type of setup has many moving parts and dependencies, and would be a hassle to maintain. If the setup would be problematic with two languages, adding more languages would make the whole system unnecessarily complex.
Another problem in this approach was that the data that SomeBuddy has collected is highly sensitive and the core of the company’s value/IPR. This makes using outside resources for translation a touchy subject.
The advantage of word embeddings
When you have a natural language text classification task at hand, the first thing you need to do is represent your data in a numerical format. There are many ways to do this ranging in complexity, but today the most common approach is the use of word embeddings, made popular in 2013 with the release of the word2vec algorithm. Word2vec is an unsupervised algorithm that produces vector representations of words based on their appearances in a large body of text (known as a “corpus”). The algorithm embeds words in a vector space in such a way that similar words are embedded close to each other, and includes some syntactic and semantic properties in the word’s relative locations.

The standard process of using embeddings in a classification task is to either 1) use your own corpus to produce the embeddings, or 2) use premade general purpose embeddings for your language. The upside of the first approach is that if your corpus contains highly domain-specific words, you will be able to generate embeddings for them. The downside is that you will need a large corpus to generate good quality embeddings. For the second approach, the upside is the corpus already contains high-quality embeddings for a large vocabulary, but the downside is the language might not contain words specific to your application domain.
How language-agnostic word embeddings can go further
The main thing to note here is that the embeddings are generated for a specific corpus and a specific language. This means that while you can take embeddings generated for one language and embeddings generated for another language, they are not compatible at the application level.
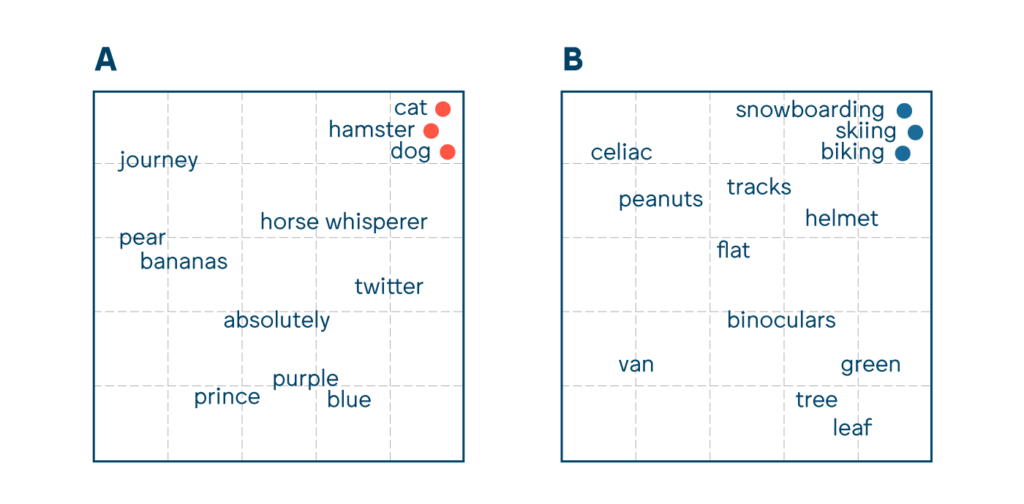
For example, let’s imagine two languages: language A and language B. In language A you have one embedding with words like “dog”, “cat”, and “hamster” that are located in a corner of the vector space that groups together pets and pet-related concepts. In language B, this same part of the vector space might be inhabited by completely different words, grouping sports like “skiing”, “snowboarding”, and “biking.” Because of this you can’t just combine two languages into one model using their own embeddings and try to train a classifier using the embeddings, because the result would most likely be a mess that doesn’t make logical sense – “pets” and “sports” are not the same thing, and a hamster has little in common with snowboarding.
Luckily, there have been some recent developments in producing language-agnostic embeddings. The concept behind them is intuitively simple, although technically advanced: the embedding for the English word “photo” is the same as the embedding for the Spanish word “foto” and the Finnish word “kuva”.
Promising results for SomeBuddy
We developed a language-agnostic version of SomeBuddy’s crime detector using Facebook’s LASER model for the embeddings, then deployed it into production. This gave us the capability to train a classifier that does not care about the input language. Any given sentences in a language supported by the model will get roughly the same embeddings and will thus be classified the same. As an added benefit, any new data in any language increases the performance of the model for all languages, instead of only for the target language.
The multilingual model solved the issue of not having representative data in Swedish. This allowed SomeBuddy to hit the ground running and start operations with support from the machine-learning component of the system immediately, instead of waiting and gathering enough data. Expanding to any new country will also now be straightforward on the machine-learning side since the crime detector will be able to classify incoming messages in any language supported by the model (over 90 languages are currently supported by Facebook’s LASER model).
So what comes next? The SomeBuddy team will use the same system of agnostic word embeddings to expand to Germany and the UK, with the goal of dramatically increasing the reach of the service.







