

30000 lines of client-side JavaScript. No tests. Two difficult TV deployment platforms with poor tooling. Strong dependencies on poorly documented external APIs. The task: add support for a third TV platform to the two supported platforms and switch to a new backend with a different API. How can we do this without breaking things?
One approach is to add tests incrementally- end to end tests to avoid breaking functionality and unit tests to aid with refactoring. But this was mostly user interface code on TV platforms with poor and varied tooling. Automated user interface testing on each platform would be challenging if possible at all. Manual testing on each platform was time consuming due to slow and inconsistent deployment tools.
Some parts of the application could be tested and this was a part of how we made this change. But the more interesting idea we tried was to refactor with types.
The approach: refactoring with types
The idea: introduce minimal typing to the code base. Add strong typing around a specific area to be changed. Make the changes, leaning on the compiler as an aid. Move on to the next area, incrementally adding types as we go.
This seemed like a nice fit for the project:
- No run-time dependencies. Some of the platforms had strict dependency requirements (read: ancient JS versions), but types are used only at compile-time.
- Shortens feedback loop. Deploying in this project was slow and flaky and tests were nonexistent, but compiler errors would come immediately and tell you how you broke things.
- Documents external APIs. The platform APIs used in the project were sometimes poorly documented, and types tell the story more clearly.
- Low typing overhead. The project was mostly vanilla JavaScript, so there was little time-consuming typing of libraries to worry about.
To experiment with the idea, I added strong types to a full path of code from UI to server calls and made breaking changes to see if the process and feedback felt useful. I tried this with both Facebook Flow and TypeScript.
Trying Flow
Adding Flow to the project involved steps like the following:
- Tagging files to be checked by Flow with /* @flow weak */ (using Flow’s weak mode).
- Adding type annotations as comments, e.g. var msg/*: string*/.
- Fixing errors:
- Unreachable code – delete it.
- Unresolved names and properties – declare them as any types.
- Null values – type as nullable or add null checks (see below).
- Unreachable code – delete it.
- Unresolved names and properties – declare them as any types.
- Null values – type as nullable or add null checks (see below).
I typed out a path from server to the UI, tried to use a field that didn’t exist on a type, and Flow complained properly. Good. But I ran into a few larger issues:
Flow wants sane modules
Flow assumes you use rational modules. If one module depends on variables from another module, it can use the types declared for the other module as expected, assuming the module is defined as a standard ES or CommonJS module. In lieu of sane modules, this code used global singleton “module” objects in different files mashed together into one file as part of the build process.
Introducing Flow here meant introducing proper modules first. This would have meant many breaking changes before we even started adding types.
Null tracking meant many changes
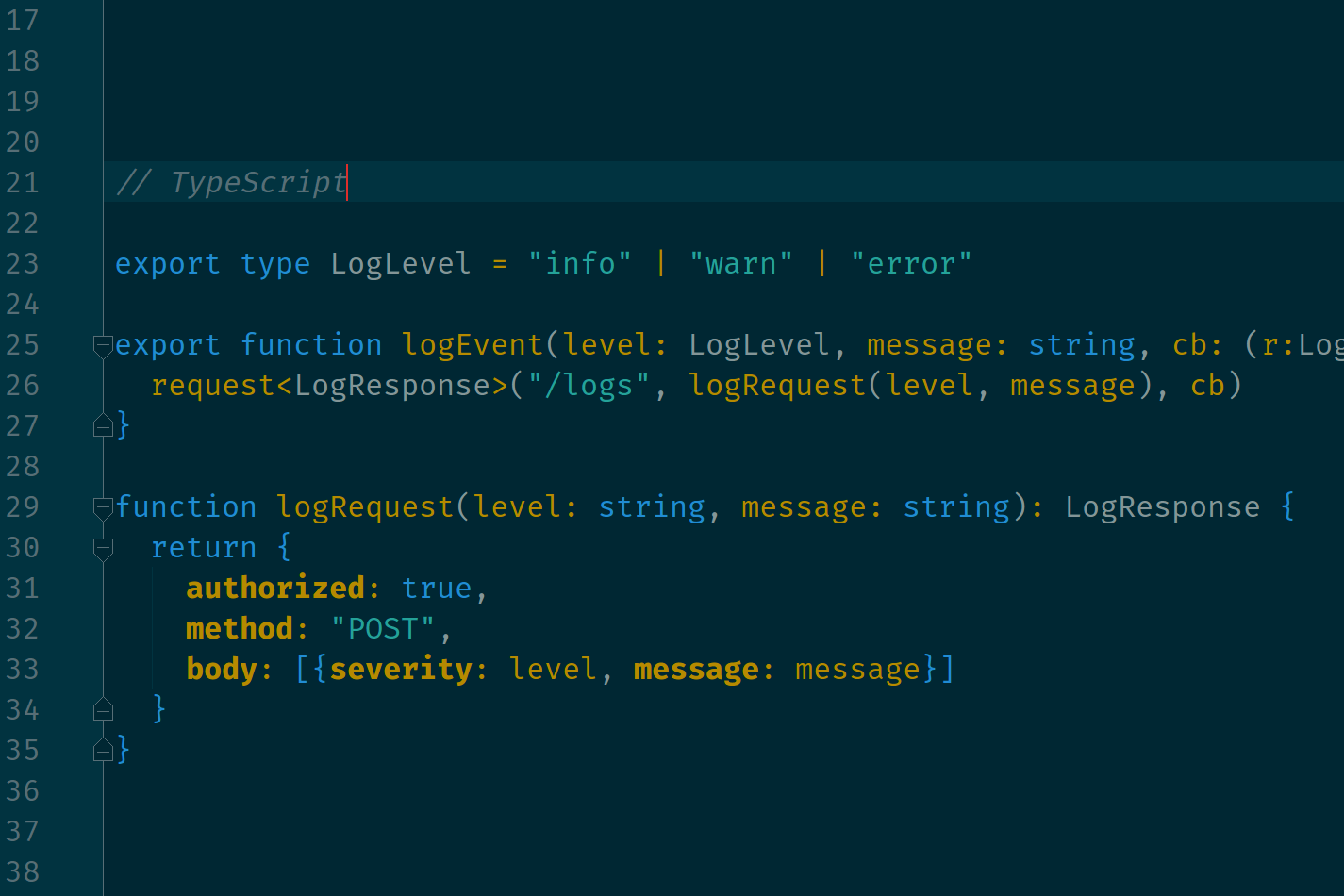
Flow uses nullable types. If your variables can be null or undefined, this must be declared in the type e.g.
![]()
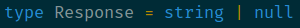
In general this is a Good Thing. But this code made extensive use of null values, which Flow rightly complained about. Fixing null errors meant either removing the uses of null to make a variable non-nullable or typing variables as nullable and added null checks wherever the variable is used. In the long term this would clean up the code base. In the short term this meant a large number of potentially breaking changes to introduce Flow to the project.
Tooling was limited
The Flow type checker itself worked quickly from the command line. The tools were easy to set up and use. It allows starting a server daemon to incrementally re-check types when run. The type errors were explicit and useful. However, editor support at the time was essentially non-existent. You couldn’t, for example, view errors inline within an editor like Intellij IDEA or Emacs. Note that this has changed more recently, however.
Trying TypeScript
Adding TypeScript required similar steps as Flow, with the addition of adding the TypeScript compiler to the beginning of the build process. The steps were straightforward:
- Rename “.js” files to “.ts”.
- Fix errors, mostly by sprinkling any notations.
- Declare global variables from other files, initially in global “.d.ts” files.
Typing out a path from server to UI and breaking the type guarantees worked as expected.
Choosing TypeScript over Flow
Ultimately I went with TypeScript, almost as much for the drawbacks of TypeScript as for the benefits.
- TypeScript namespaces were an easy match for the unconventional global object modules used in the project. This made it easier to add typing to our project modules as they were, while eventually transitioning to conventional ES modules.
- No null-checking in TypeScript by default made it much easier to initially type our code base.
- TypeScript tooling and support were much better.
I like both TypeScript and Flow. Here are a few differences as I see them:
- TypeScript infers little and gives little value without type annotations, while Flow tells more out of the box.
- TypeScript has much better tooling. The Flow type checker itself was easy to use and worked well from the command line, but editor support at the time was bare bones or nonexistent. TypeScript Intellij IDEA and Atom support was decent. More on that later.
- TypeScript has better documentation and support. The Flow documentation was sparse but decent and has been improving. But the TypeScript documentation is really good: the TypeScript Handbook, Language Specification, roadmap, and openly commented issues are incredibly useful. TypeScript as a project also seems to have much more momentum behind it and the compiler has received a number of significant improvements in the few months of this project.
How we introduced TypeScript
Introducing TypeScript and types to all top-level module elements in the 30000 line code base took two to three days. Initially there were a large number of any types. As part of this process the existing modules, defined as objects in the global namespace, were converted one by one to TypeScript namespaces via Vim macros, find-and-replace tools, and carpal-tunnel inducing Vim fu.
After this effort, types were added incrementally as a part of normal development. Whenever a certain area of the code was modified, types were first added around the areas to be changed. Then the changes were made, leaning on the compiler to tell when data used was not available, variables were missing, and so forth.
Initially there were both explicit and implicit (inferred) any types throughout the code. At some point any types were required to be explicit (via tsconfig noImplicitAny) and gradually most any types were replaced with more specific types. After nine months of development there were still about 485 any types in the code base, mostly related to the interesting “class” structure that had been used for UI elements in the project. More on that later.
At some point the TypeScript namespaces were replaced in one go by normal ES modules. Browserify was introduced at the same time to merge these modules into one file with proper modules, as TypeScript doesn’t handle this.
Where TypeScript worked
Refactoring
Adding types and in particular using TypeScript in Intellij IDEA was a godsend for refactoring. It removed a huge amount of manual checking that would have been needed for even basic changes.
The compiler would tell things like:
- Is my function called with the correct number of parameters?
- Is this variable being used?
- Does the value I am using exist?
- Does the field I am using on this value exist?
Understanding the code base
Question: what data is being used from the backend APIs in your JavaScript application?
JavaScript answer: find the code that calls an API and receives data as an opaque object. See where the data is passed. Follow that data and see where it gets passed next. Track how the object is modified along the way. Grep to the eventual places where the object is used and write down in your notes each field that is used. The process requires careful, focused navigation through the entire code base, good notes, and significant amounts of grepping.
TypeScript answer: add types to the API call, initially giving it your best guess of the correct type e.g. an empty object type.
![]()
Add type annotations to every place this function is being called. The compiler will tell you if your type is wrong. In Intellij you get a red squiggly line under your incorrect assumptions.

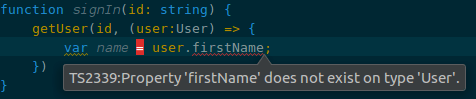
So you update the type to match reality:
![]()
Continue adding type annotations everywhere the data is used and updating your types until the types match reality. This still requires much of the same navigation as above, but you offload a large portion of manual grepping and note taking to the compiler.
Making tools better
TypeScript makes Intellij IDEA amazingly better. My tooling experience has started good and improved during the time I’ve used TypeScript. Inline errors point directly to code issues, short-circuiting the write-debug cycle. Tools like navigating to functions, renaming variables, inlining functions, autocompletion, and finding variable usages work immensely better than with vanilla JavaScript. Much as I appreciate minimalist editors, combining Vim keybindings with refactoring and navigation tools makes me an absurdly more effective developer. It would almost be worth it to ignore types and use TypeScript for this reason alone.
Documenting external APIs
Some of the external APIs we used had poor documentation or were entirely undocumented. Adding type annotations to these APIs documents our own knowledge about those APIs and helps later when using the APIs. It’s also a convenient place to put comments about the sources of documentation, implicit assumptions and so forth.
Making code dependencies explicit
Types document the flow of data throughout your app. In our case the UI and data were not clearly separated. It was a mess to trace the source of data down to the leaves of the app where the data was being used. Types made these dependencies explicit and much easier to follow.
Finding bugs
In some places adding types revealed bugs. For example, incorrect titles for images were being displayed in some cases because they relied on the old API data which no longer existed. Adding types caught this immediately because the new API data types did not contain this information.
In another example an image was fetched by passing in a string to a function and receiving the image URL. It turned out that the string contained a typo, which we found after making the function take a string literal type.
In a number of places we could safely remove dead code only because we knew that the data did not exist on the new types.
New tools, old environment
Introducing TypeScript brought most of the ES6 benefits to a legacy JavaScript project without introducing runtime dependencies. It also did not require another heavy tool like Babel, although we did need Browserify to get proper modules.
Where TypeScript failed
You can’t always trust the compiler
TypeScript is explicitly unsound, which could lead to some surprising errors. In practice we did not run into these. There are other cases, however, where TypeScript works exactly as intended, but it might not be how you expect.
Here’s a type puzzle. Explain the type checks in 1-5.


Answers:
- 1) is OK because all fields of the empty object type {} exist in value { foo: “hello” }.
- But 2) fails because even though we can assign an object with property foo to a variable of type Empty, the variable type doesn’t have foo in it so we can’t use it.
- 3) fails because it’s missing the text property of type Msg.
- But 4) also fails even though it has the text property, because you can’t directly assign or declare an incompatible type (with the foo property).
- But 5) is OK, because even though variable d of type { text: string; foo: string; } is not assignable to type Msg, a value of type { text: string; foo: string; } is compatible with type Msg.
There are subtleties here that make it difficult to completely trust the compiler.
Type inference doesn’t go very far
The limitations of TypeScript’s type inference can be surprising. For example, TypeScript will rightly complain about this:

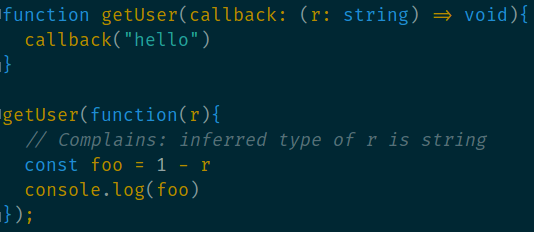
but is OK with this:


It’s easy to see why this doesn’t generate a complaint, but this might be unexpected, which brings me to the next point.
TypeScript requires many type annotations
In the above example the two cases are semantically equivalent. The problem is that the compiler is able to infer the correct type of the callback parameter in one but not the other. In the second case the compiler infers the any type. To make it easier to trust the compiler, it’s useful to disable implicit any types (via tsconfig) and/or explicit any types (via TSLint). The compiler would then complain about the second example because of the inferred any type.
TypeScript doesn’t give you much support for free. If you add type annotations, your editors get better and the compiler will aid you in finding errors. If you don’t add type annotations or if you use many any annotations, TypeScript won’t help much. In practice this means you will be writing a lot of type annotations.
Types are still your assumptions
When receiving data from external sources, the type embodifies your assumptions about the data. You are expecting to receiving an object, with a field name foo, with an array of bar, and so forth. These assumptions are not checked by the compiler. You still need to validate input data if you want to be sure. The types are only as good as your assumptions.
Typing can’t always be incremental
In most cases we were able to add typing in small chunks, but not always.
A large portion of the UI code in this project used a hierarchy of view objects. This hierarchy would map well to TypeScript classes, but typing it as classes is difficult to do piecemeal. If you add types only to a parent class, the compiler complains when the child class uses its own fields that do not exist on the parent class (and are not yet typed on the child). If you add types only to a child class, the compiler complains when you use fields from the child that are only defined on the parent class. In practice it means that the typing of this whole hierarchy must be done in one go.
Circular dependencies
TypeScript doesn’t allow circular dependencies. Sort of. TypeScript was happily compiling our code, circular dependencies and all, for months until one day it broke. Maybe it was just serendipitous that the dependencies were loaded in the correct order before, but it stopped working. We painfully refactored the circular dependencies all away. Lesson learned: no circular dependencies in your TypeScript code.
Was it worth it?
Adding TypeScript to this project was an experiment to see if adding incremental types to our code would make it easier to do large refactorings without introducing large breaking changes. The experiment was a success.
Converting the project to TypeScript and adding the initial types took a few days. This was the only additional work that was required solely due to adding TypeScript. After this types were available as another development tool and were expanded incrementally to the rest of the code as a part of normal development. Refactoring was much easier with type checking and it removed a huge number of manual checks and careful grepping that was previously needed to change code.
A few items made this project a particularly good fit for TypeScript:
- Few dependencies meant little time typing out external libraries.
- The environment was difficult to deploy to, so compile time checks gave dramatically faster feedback.
- Tests were difficult to write, so types added a much needed safety net.
- TypeScript support for older versions of JS allowed us to use new JavaScript features at compile time and remove at run time.
The biggest drawbacks were the typing overhead of adding annotations nearly everywhere and the uncertainty about type guarantees in certain cases such as those discussed above. It’s not PureScript, but types were useful and they were easy to add incrementally. In this case it would have been more risky to continue with vanilla JavaScript than to introduce types.
4/5 stars. Would use again.







