

Last fall, one of our K Group’s AI team members was using Google search and started to think about the full search term suggestions it gave. “Why don’t we provide this functionality?” he asked. If the product search proposed relevant search terms already from the first letters, the user experience would improve significantly.
We had already provided intelligence to the product search of K Group’s grocery web store, K-Ruoka, so it was a familiar domain to us. After a short discussion, we agreed to try it out. Within two working days, we had a new REST API providing the functionality running in our production environment. After testing with designers, it only needed a few minor tunings before it could be added to K-Ruoka web store. Additionally, the same functionality was easy to duplicate for other business divisions of K Group.
So how did we manage to turn our idea into a production-ready scalable component so quickly? What had we done earlier to support the act?
In this blog post, we’ll first introduce the background of the K AI team and then share some things that nowadays make our work much easier. We’ll go through our perceptions on how removing separate roles for data science, data engineering, and DevOps has reduced risks, the benefits of having our own environment, and the improved efficiency of the team. We believe these learnings can be valuable to all the organizations that are facing a similar transformation.
But let’s start by going back to the beginning of K AI.
The constructing of K AI
As data science has been around for a while, many companies have gained a lot of experience in building machine learning models. However, models must be developed into components that can be tightly integrated to other production systems. It requires new skills, attitudes, and ways of working.
We have been working in K AI, the AI development team of K Group for four years. K Group is a major Finnish trading sector company.
In its strategy, K Group has decided to focus on customer orientation and digital services. In 2016, K Group chose to invest in AI in the long run and put together a dedicated team. The team started to build AI-utilizing capabilities to create integrated, automated systems for production use.
After the first proof-of-concept was successful, it was clear to us that we wanted to build a sustainable ecosystem for development instead of multiple separate quick proofs-of-concepts to avoid difficulties in maintaining the solutions. Building this kind of modern, cloud-based development environment was still something relatively new in K Group in 2016. We had the privilege to have autonomy regarding tools and technologies, which led us to build a completely new environment with all the tooling and monitoring for our own use.
The long-term commitment from K Group combined with the team’s autonomy has proven to be an excellent choice, as it has allowed the team to look beyond low-hanging-fruits and truly invest in its capabilities. Building everything from scratch is demanding but has led to many benefits, some of which are surprising.
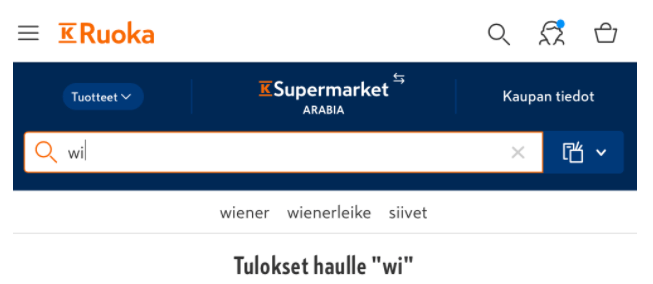
Predictive search results for search term “wi…” in K-Ruoka web store. In addition to “Wiener schnitzel” it suggests “siivet” which is “wings” in Finnish, as the English version isn’t available in the product names and therefore “siivet” gives better results as a search term.
Sharing responsibility
Creating AI in your own environment requires a lot of skills and knowledge. In addition to expertise in programming and machine learning, one must master areas such as continuous integration, infrastructure-as-a-code, computer networking, security, and high availability. These are not the topics data scientists typically excel at.
The responsibility for creating and maintaining infrastructure tends to fall to just one or two team members. It might feel like the easiest and best approach, but when holiday time gets closer, or someone leaves the team, things get problematic. It happened to us, too. To not make this mistake again, we started to spread the knowledge systematically across the team. Our goal is that everyone is comfortable with all aspects of our development work.
Additionally, when everyone bears responsibility for operational duties and infrastructure, it has a significant impact on the quality of our work – knowing that it’s you and your teammates who will fix the problems in the future makes you care a lot more about the maintainability of the solutions. This increased our team members’ motivation to learn the skills that are traditionally not part of data science.
The benefits of the own environment
Having full control of the entire development environment certainly speeds things up. There is no need to communicate between infrastructure, development, and operational teams because, well, they are all to be found in the same team. If we think that using some brand-new service might be useful for our team, we can try it out. If it seems to fit, we update our infrastructure accordingly.
As everyone in the team is familiar with the basics, we get a lot of support and help from each other. It also helps in communicating our results to other people in the organization. Any team member can discuss new ideas directly with our users, which ensures there is no information lost in the process.
The ability to take responsibility for all aspects of the development environment also creates excellent learning opportunities. There are so many details to know that it’s fair to say that no one knows everything, or ever will. Are you a world-class expert in fine-tuning hyperparameters of dynamic linear models? Great! You can teach me all about that, and I show you how you can use NAT Gateway to get access to the internet from a private network. Familiar with both of those? Move on to learn how to make our data pipelines faster. According to our experience, continuous learning is one of the most important things, and having wide responsibilities provides excellent ways to keep us learning.
Scalability: Efficiency and Reliability
Having the complete shared responsibility of our own environment and solution as a team has made us focus on creating scalable, reusable components. For example, our 12 different REST APIs all share the same base code, and they share the same generic Terraform module. Similarly, our typical daily batch calculations share the same generic Terraform module. Together they allow us to create new batch calculations and new APIs quickly and have them running in our environments with only small tuning of configuration files and a single command with our internal deployment tool.
Having scalability and reusability in mind isn’t limited only to software development or operations oriented components, but is also relevant to statistical models. However, it is essential to develop them together with their first user and use case. This way, the usefulness of the results can be verified and tested in the actual use along with the design where they will be part of. Otherwise, there is a risk that the model works well based on theoretical measurements, but the results are still not usable at all.
Conclusions
Back to the original question: How did the decisions we had made help us create the first version of the predictive search API so quickly?
It all comes down to having a carefully built solid base and knowing the previous development work. The intelligence for the predictive search was created by reusing an existing statistical model. The API was put up and running by utilizing generic components and internal tooling, which allowed us to build a new API from scratch in a matter of a few hours. They were available because we were bearing responsibility for our environments, we shared a DevOps mentality, and we were continuously improving our tools and processes.







