

Reaktor’s data scientists completely revamped the popular service Kannattaako kauppa, estimating apartment prices across Finland. Find out how the pandemic affected the housing market – and how we uncovered the information.
A few years back, we created a service that made quite a splash. We showed the trend in housing prices in almost every single area in Finland and put our estimates on a map. Now, after a tumultuous year with the pandemic, our statistical model deserved a complete facelift.
Building our model on the rare treasure that is the data provided by Statistics Finland, we used demographic covariates to predict prices across the country, even in areas where apartment sales were scarce. Our thoroughly updated service shows that last year was indeed unpredictable and peculiar, with price growth spilling from city centers to the suburbs. Here’s what we found:
- 2020 was a peculiar year, looking anomalous even on our maps.
- The steepest price growth didn’t happen in traditional areas in city centers. Instead, we saw a bunch of unexpected risers in the suburbs and outside big cities.
- Growth happened throughout the western half of Finland, not just around our capital Helsinki. You can check out our list of the top 10 highest and lowest growth areas here.
This blog post is a deep dive into the statistical model we used to map housing prices. Join us to discover the characteristics and quirks of demographic covariates – and some insights about the housing market along the way!
The foundation: Why we need demographic data to estimate housing prices
In 2016, we needed apartment price estimates for areas where those were not provided due to small population size or too few transactions. We ended up creating a model based on the hierarchy of postal codes and updating it from time to time.
Although the model, described in detail here, served its purpose well years ago, there were two main drawbacks: first, spatial smoothness, or generalizing of evidence spatially, is based almost entirely on the postal code hierarchy (the exception being population density). Second, there is the quadratic temporal form. The pandemic brought in a bunch of new anomalies and we realized we needed to build something that takes the peculiarities of single years into account. It is more interesting and fits the data better.
In the new model, predictive power mainly comes from demographic covariates: 23 variables selected from the Finnish open data that describe the geographical extent, people, households, apartments, and professions of the postal code areas. The covariates have yearly coefficients in the model, so the model has gained temporal flexibility compared to the original.
The postal code prefix hierarchy is still there, but with the quadratic term dropped. This allows the local price levels and trends to deviate from the predictions of covariates. However, the postal code hierarchy is unlikely to have intrinsic predictive power: it is just a proxy for spatial adjacency. Now that efficient implementations of true adjacency-based spatial random effects are available, eventually we would like to adapt those to our model to either provide parametric deviations from predictions of covariates as postal codes now do or a fully nonparametric spatiotemporal random effect.
But why do we need “predictive power” with past prices? When an area only has a few actual apartments sold, its price level and especially the trend are largely unknown. By accident, the few sales can be on the high or low side of the range. Many “top performers” on basic housing price ranking lists can turn out to be statistical flukes.
A good model will, if nothing else, show this uncertainty. And a good model also generalizes temporally and over similar or nearby regions, partially filling the holes and uncertainties in the data to a degree where continuities in the actual prices support it. After all, we know that there is temporal, spatial, and demographic regularity in the real world.
We need statistical modeling to fill holes on our map. Around 90 percent of the reported housing sales in Finland have taken place in 18 percent of the postal code areas. Meanwhile, some 93 percent of the regions have less than a hundred sales transactions, and 73 percent have less than ten. There are also areas with no apartments at all! And even in areas with apartments, data is sparse.
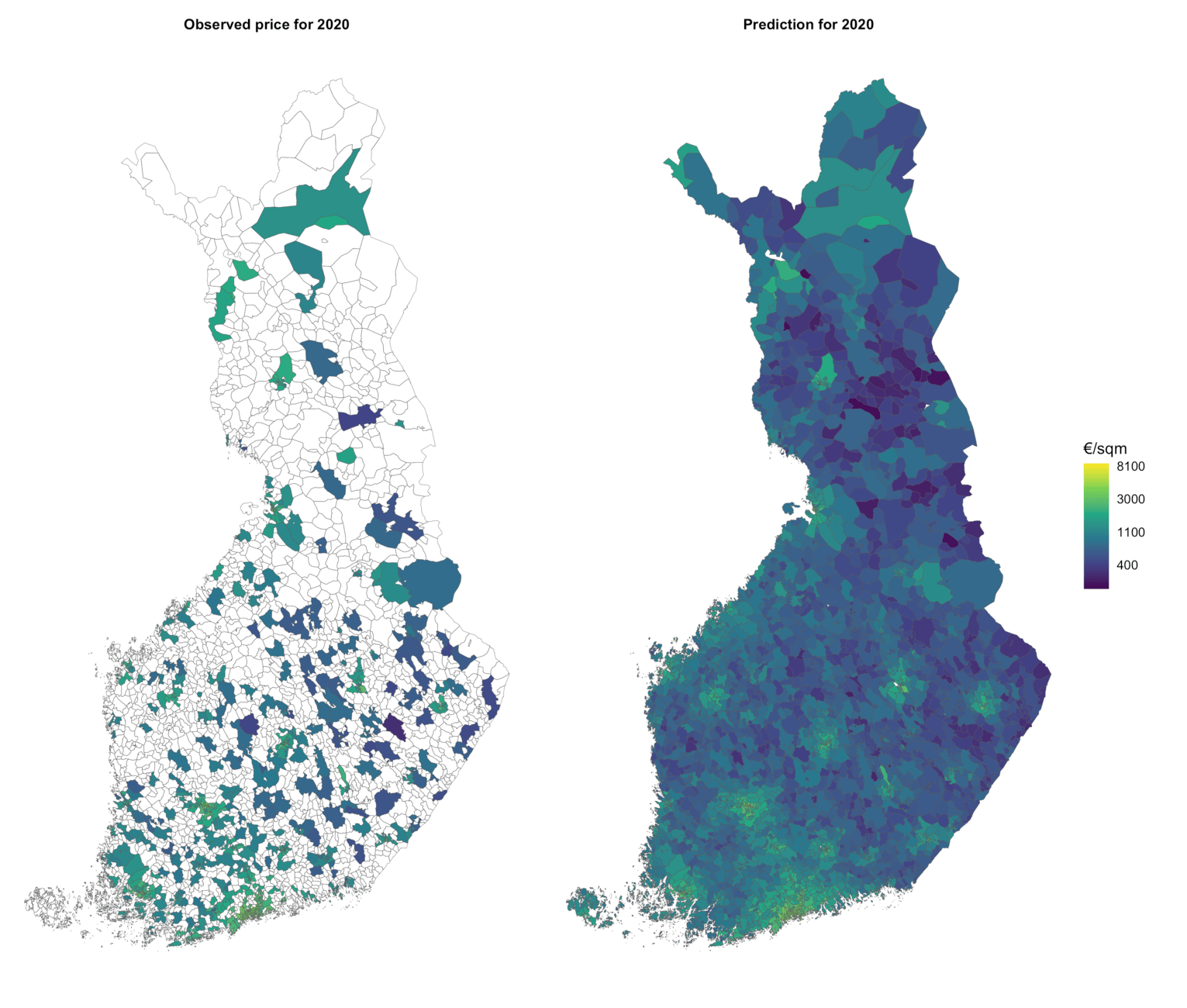
The price data is relatively sparse. Modeling helps to fill the holes and refine estimates in areas where only a few transactions are available.
As an additional benefit of including demographics in the model, we see how they affect prices over time. Covariate coefficients provide us exciting insights into the effects of the pandemic, but before taking a closer look at those, let’s dive into some details of the model.
The framing: How our model is made
We use demographic data from Statistics Finland. The database called Paavo contains some 100-odd entries per postal code area, with information about population, households, employment, jobs, properties, and so forth.
Based on a nonparametric model, we picked around 20 of the most relevant entries to keep the number of parameters reasonable and the results interpretable. Then we normalized the figures with relevant counts, e.g., number of service jobs by total number of jobs in an area, and used the (inverse) logit transformation to get good covariates. Finally, the covariates were standardized.
Currently, we apply shrinkage to the fractional covariates, the uncertainty of which varies by the denominator. Later on, we would like to take the uncertainty to the primary model to avoid outlier-looking covariates and very uncertain price estimates on some population-wise small areas. In the current service, we leave such areas grey on the price-change map, along with other uncertain areas.
The open data provided by Statistics Finland is a rare treasure: it’s accurate demographic data with a high level of granularity. However, due to understandable privacy reasons, data from postal code areas with only a few people is censored. Finland is sparsely populated, so the amount of censored entries is non-negligible.
As one of the key purposes of the model is to estimate property prices in areas where we don’t know them, we cannot simply drop censored data points. Instead of naïve zero or mean imputation, we use the state-of-the-art multiple-imputation package Amelia II. In the future, missingness could be included in the core model.
Another challenge in the demographic data is its snapshot-like quality: The most recent information is from the years 2018 and 2019. Complete temporal covariate data is publicly available neither as time series nor as yearly snapshots. If it were, year-wise covariates would improve accuracy and make interpretation of temporal changes of covariate coefficients safer.
Is it dubious to use a snapshot to predict prices of past or following years? Each year has its own error variance in the model, and demographics assumably change slower than apartment prices. We just have to be careful with interpretations, especially causal ones. For predictions, using a snapshot of demography is obviously better than not using demographics at all.
The independent variable we are predicting is the average price per square meter in all apartment types. An interesting non-trivial future challenge would be to use even more sparse data about apartments with various numbers of rooms and estimate prices specific to the number of rooms. Modeling apartment heterogeneity would improve overall price estimates, and in dense areas, provide more specific price information. And, of course, the development of prices of different apartments may sometimes diverge in interesting ways from the viewpoint of covariates.
Many covariates are computed as fractions of certain kinds of people, households, or other objects. Uncertainty of these varies by the denominator, which is related to the size of the area. We did shrink the fractions, but it would be better to take covariate uncertainty into the primary model.
A top-notch model is of no use if its results are not communicated properly. Presenting prices and uncertainty on the same map is a challenge. Currently, the only indication of uncertainty on the map is the grey areas where a credible interval of prices crosses zero. Obviously, this confuses high confidence of almost exactly zero with a total lack of information and anything between and could be revised the next time we update the model.
The inspection: When in doubt, trust the empiria
Especially in city centers, there are sometimes hundreds of transactions per slot. The mean price for the area is then known quite well. For instance, in Etelä-Haaga of Helsinki (postal code 00320), there were 386 apartments sold in 2019, with the log-price 8.54. We don’t know the population variance, at last not without modeling, but we can trust the relative accuracy of the mean: 386 sales, who can argue with that?
If that happened to be an anomalous year in Etelä-Haaga, for example, due to extensive construction work or other transient effects, the model has no way to predict that anomaly. So there is variation unique to the areas that the model doesn’t catch, and sometimes we see it when there are plenty of transactions. On the other hand, when transactions are few or absent, local anomalies are not visible, but we have to assume they may be there. So the model needs an error term that is independent of the number of transactions.
In cases where we know the “empirical truth”, like in Etelä-Haaga, what should we communicate? One can either communicate the price level and trend from the model and say: “This is it assuming the smoothness of the model. The rest is errors.” The alternative is to make a compromise: “All right, in this particular slot, the evidence trumps the model, at least partly.”
In earlier iterations, we have communicated the smooth trends from the model. This time we decided to try to compromise. But how to make it? We just need to redraw the border between modeled expectation and error.
In the original model, our error variance already had two parts, one independent of the number of transactions \(n\), and one that scales with \(1/n\), thereby assuming independent transactions within a slot. In the new model, we take the first part away from error variance and place it into the model as a slot-specific random effect (details below).
As a result, the prices you see on the site are now more realistic in areas where good evidence is available.
The blueprint: What the model looks like
The essential parts of the model are:
\begin{aligned} h_{it} &= x_i^T \beta_t + \sum_l \left( a_{li} t + b_{li} \right) + u_{it} + \epsilon_{it}\;,\\ u_{it} &\sim N\!\left(0 , \sigma^u_t \right)\;,\\ \epsilon_{it} &\sim t\! \left(0,\, \frac{ \sigma^\epsilon } { \sqrt{n_{it}} },\, \nu \right)\;. \end{aligned}
\( \)
Of indices, \( i \) refers to the postal code, and \( t \) is the year. Then \( h \) are the observed log-price, \( x \) are covariates, \( β \) are (yearly) covariate coefficients. The sum is the “pseudo spatial” random effect built on the postal code prefix hierarchy, with prefix levels \( l \), and varying trends \( a \) and intercepts \( b \). This relatively rigid structure is loosened by the \( i \times t \) -level random effect \( u \). Model terms up to this point are supposed to represent the underlying actual prices. Note that the last term has yearly spread out, allowing some years to be more deviant than others.
Finally, finite numbers of observed transactions \( n \) cause “measurement error” \( \epsilon \). Assuming independent transactions, the variance of this error scales with \( 1/n \), but we have left space for outliers using a Student-t distribution with its degrees of freedom \( v \) parametrized to the model. They are fitted to \( ν≈2 \).
Note that if the measurement errors were gaussian, \( u \) could be marginalized away. (We tried that, and it, of course, accelerates the fitting.) Although technically the parameter set (\( ν, \sigma^\epsilon, \sigma^\mu \)) is well identifiable, based on various trials, we are not convinced that estimates of these are robust enough to assumptions that do not quite hold.
On the website’s price time-series visualization, \( \exp h \) are the black points denoting observations and reported price estimates, and credible intervals are the part of the model without measurement error \(\epsilon\), that is, \( \exp (h−\epsilon) \). On the map visualizations, because covariate uncertainty is not yet in the model, we use the gray color on areas with less than a hundred residents. Estimates are entirely missing when there are no residents.
In addition to the structure detailed above, the model naturally has priors, and for example, covariances for coefficients \( a,b \). If you are interested in the details, take a look at the source code.
The surroundings: Did covid-19 put urbanization to a halt?
Now, back to the big picture. 2020 was a peculiar year, even on our maps.
The main predictors in our model are living space per person and mean income. Their coefficients increase monotonically year by year, implying increasing centralization: high prices rise, and low prices become increasingly cheaper. If one looks at the principal variation of the year \( \times \) covariate matrix, the main axis is almost monotonic in time, reflecting this development. The second component is a complex combination of the not-so-demographic covariates about population, size, and average space. The component could vaguely be called a suburb index. But the variance of the second component is only 14% of the first one.
The picture below illustrates how apartment prices have changed over the years from the perspective of these two components. The year 2020 certainly looks anomalous, although posterior uncertainty is pretty high on PC2.
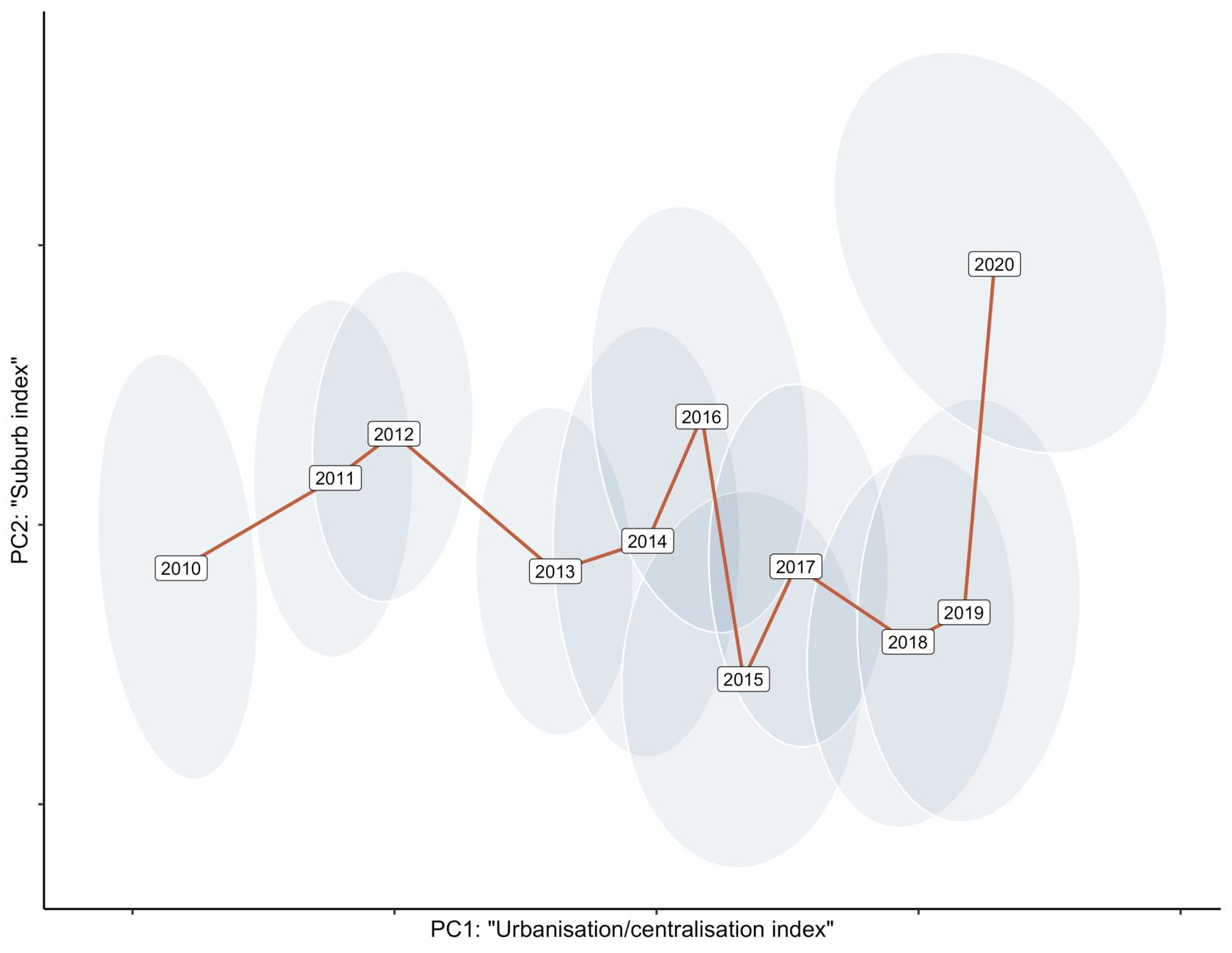
Space of principal variation of the covariate coefficients by year. PC1, the axis of explaining most of the variation, is almost monotonic in time, representing continuing urbanization. PC2 reflects the remaining variation, possibly related to prices in the suburbs or, more generally, less crowded areas around city centers. Ellipses denote 80% credible areas.
The phenomenon is readily present on our maps and in the smaller map below. Prices have increased in some previously fairly stable suburbs, whereas city centers received relatively modest increases. Outside the largest cities, prices used to decrease, but now the estimate is (weak) growth almost all across the western half of Finland.
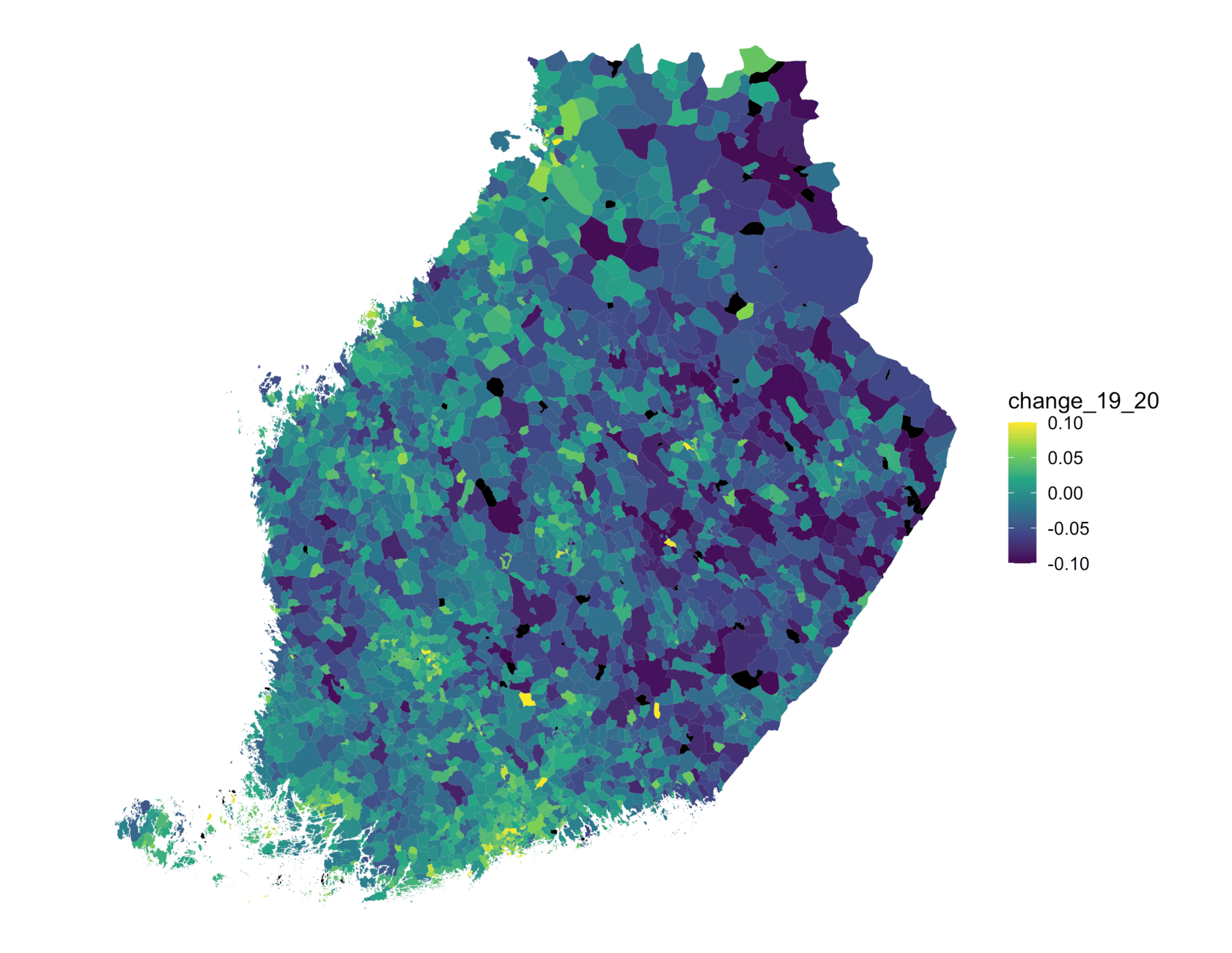
Change of posterior-median prices in southern Finland (2019—2020) shows a west-east division and growth in less crowded areas.
Another way to look at the peculiarity of 2020 is to look at the coefficients of some of the covariates as time series, illustrated below. Here, it is enough to say that a positive value predicts higher prices and vice versa. Clearly, small living space is still related to increasing prices.
However, the effects of, for instance, shares of high-school graduates and employed people, and living density are somewhat different from previous years. But not all observed price changes, like the east–west division or maybe suburbs, are not easily expressed with the covariates, so it is not a surprise if changes in covariate coefficients are somewhat hard to interpret.
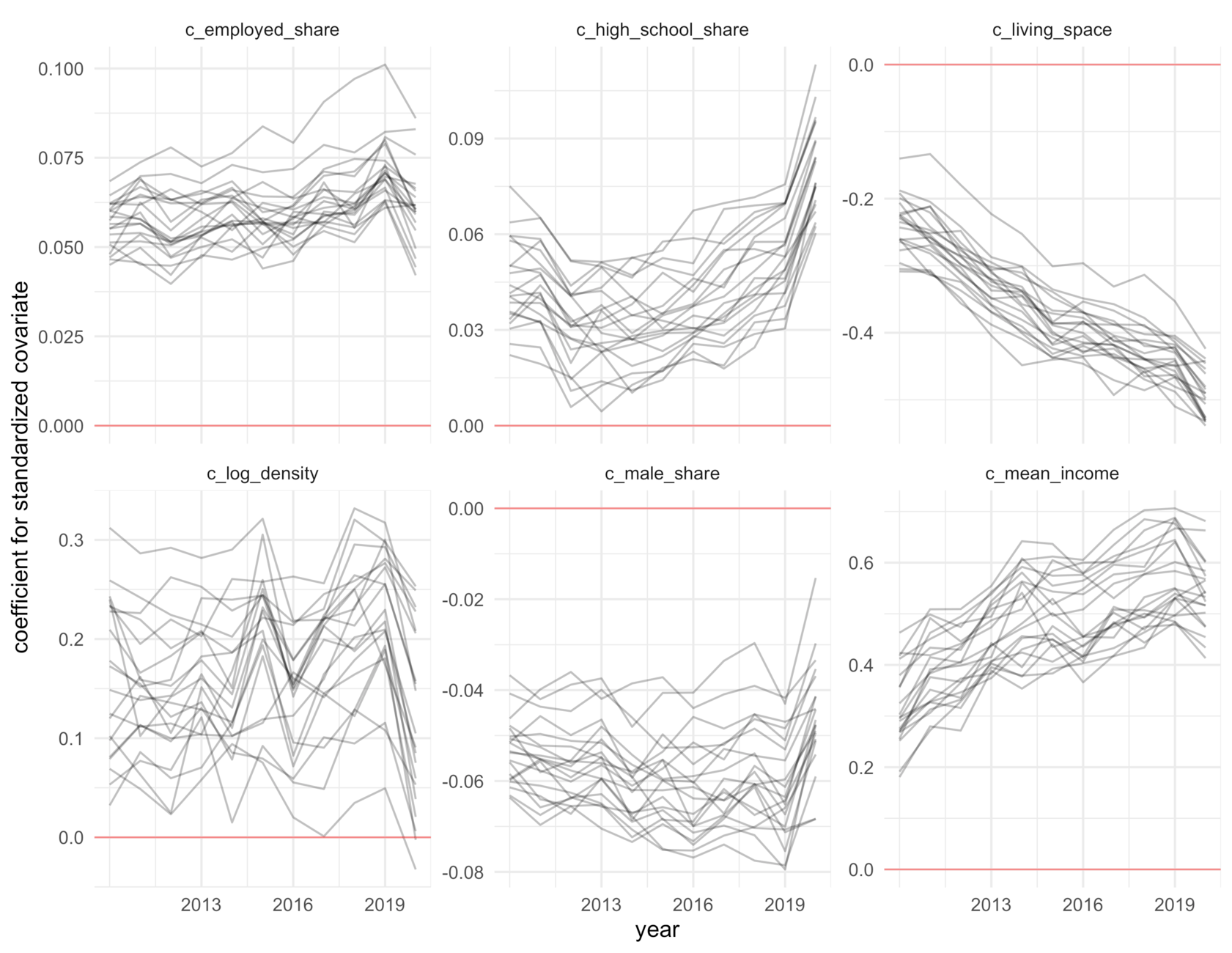
Coefficients of selected covariates, as time series. Lines are posterior samples. Note the varying scales. The most important predictors in the model, mean income and living space, for example, show a more or less constant trend, while for some covariates, the year 2020 was exceptional.
Another way to compare the years is to look at the idiosyncratic variations in the zip \( \times \) year random effect. This variation is not explained by either the postal code hierarchy or by covariates. The yearly standard deviations of the random effects are parameterized to the model and shown below. In layman’s terms, the further to the right the values of a year are, the more challenging the prices of that year are to estimate with the postal codes and demographics. Although there may be a border effect, the year 2020 looks different from the previous ones again.
All in all, 2020 was anomalous compared to the previous years. It will eventually be interesting to see how the prices of 2021 fit the pattern. Will urbanization get back on the old track, or has the lure of the suburbs come to stay?
Want to be a part of the team developing the next round of our housing price model? Check out our open positions in Data Engineering.







