

“When will it be done?” Is a question I get asked almost weekly as a software developer. Despite building software professionally for the last 15 years the sad reality is, I have no idea when something will be done and most likely neither do you.
Updated May 10, 2021: If you want to learn how to apply the method described in this blog post, Reaktor provides a specified forecasting training for that. Learn more here or email Dirk directly.
How many projects have you worked on where a major frustration was coming up with a prediction for how long it would actually take to build a feature? If you are a developer I’m sure you have been frustrated when people asked you to express complexity using a fibonacci point system, often followed by remarks that your estimate “sounds a little high or low”. If you are a product owner I’m sure you have been frustrated with developers not being able to give you a concrete timeline for that next feature you like to have.
But I have good news for you! You can actually get much more accurate forecasts using some fairly simple statistics over the historical data of your team. Stay with me, this blog post explains the basics of how you can achieve just that.
Here’s a small metaphor that highlights the real problem with answering the question “when will it be done”: Imagine after a hard day of work you get home only to find out you lost your keys. Now imagine I would in that moment ask you how long it would take to find your keys. You know that it won’t be a minute, but not a year either, in fact you're not sure if you are going to find them at all. That is what it is like getting asked when something will be done.
Estimating when a piece of software is ready for release has proven incredibly challenging. Many techniques have been introduced over the years but none have had the desired effect. Even worse, many of them take an incredible amount of effort from the team. The problem with spending a lot of time on estimating is that it can feel useful, but often is so inaccurate that it hardly yields much value to the business. Yes, you might be able to come up with an accurate estimate for very small amounts of work, but is that the information we really need? I’m not saying that the size of a feature should never be a topic of conversation, it should be, but it would be beneficial if we can have more confidence in those predictions. And here's the brutal question: what good are estimates if they hardly ever align with reality? You could have spent that time on building software.
Broadly speaking there are two ways one can attempt to predict the future. Either you make a model of how you think something will play out, or you take a black box approach where you try to derive information from historical outcomes. I believe that software development is way too complex to approach using the former method. However as it turns out most teams actually have fairly consistent outcomes unless you are operating in an exceptionally volatile environment.
The Cone of Uncertainty, a principle in project management based on research by NASA, suggests that estimates at the start of a project are up to 400% off from reality. So when I ask you to estimate something and you tell me it takes a week, in reality it is actually done somewhere between two days and a month later. But you don't really need the research to know this is true, do you? Almost everyone involved with software development knows this from experience.
What makes estimation so hard? One mistake is that software development is often treated like a manufacturing process while it is fundamentally a design activity. In fact manufacturing software is completely automated: the compiler or interpreter takes the source code and manufactures as many incarnations of the product as you need. No humans needed. All the effort is in actually designing the program. Design is inherently unpredictable because it is about creating something that did not exist before. This means there are a lot of unknowns, thus a lot of unpredictability.
Another pitfall is not taking wait time into consideration. Wait time is the amount of time work is paused after being started. When you think about estimating you mostly think about how much time it would take to complete the task in one go. However in reality all sorts of things break up the flow of working on that task. There most certainly are meetings to attend, and weekends to spend on the beach. Think about the amount of times a dependency on another team has delayed your software.
A well known example of this are integrations: getting a piece of data like a user's email from an API and displaying it on screen might not be that hard, but in reality we find that sometimes APIs don't work as advertised. They might need separate authentication, and might have their own erroneous behaviour that the implementer has to take into account.
The amount of time a piece of software design spends waiting to be worked on is incredibly unpredictable. When you start measuring the ratio of active- time to wait- time you soon realise that it is often wait- time that takes up the majority of the time to deliver an increment. Yet it is not taken into consideration when coming up with estimates.

I am here to tell you there is a more accurate way of predicting the delivery time of software and it counterintuitively involves minimising the role of human estimation. Instead you can look at the team's historical data and apply statistical techniques.
Queueing theory is the mathematical study of waiting lines. It is used for example to predict the capacity of a queue, or the speed with which things flow through the queue. It can be applied to all sorts of domains from theme parks to phone networks. And we can also apply the logic of queuing theory to our development process to make better predictions about its outcomes.
It doesn't matter what kind of project management methodology you are using, you can always think of your process as a queue that takes ideas as input and produces software as output. There is a large body of research that has analyzed such systems, the findings from which we can apply with ease to create a forecast for the moment of delivery, and the capacity of such a process.
A queue has certain properties like the amount of work in progress (WIP), the time it takes for work to go through it (Cycle Time), and the amount of work that comes out of it per unit of time (Throughput). So we can use these properties as a basis for answering questions about delivery time and team capacity.
For example, the historical throughput of your team can be used to run a simulation of future throughput. Some outcomes will be more likely than others and you can use these numbers to come up with statements like: "41 items or more can be completed in 30 days with a certainty of 85%".
The beauty of using a method like this is that it can be done with minimal effort, and it automatically updates as time goes along when more information becomes available. There is no need to sit down with the team for hours and take guesses at the size of the work items flowing through the queue. Variance in work item size is a given and taken into account when analysing the numbers.
Still with me? Great! Let's put this into practice. If we are trying to determine when a certain piece of work will be done, we can start looking at how long it generally takes for work to flow through our process.
To do that we are going to start measuring the cycle time. Cycle time is the amount of time it takes for a piece of work to go from start to finish. It's important you define what exactly those start and finish points are in your process. For example, are we measuring from the time of inception of the idea, the time of commitment, or the time that the work has started? You will have to define these boundaries consistently for your data points.
We will use these data points of our cycle times to build a scatter plot, with the measured cycle time on the vertical axis, and the completion date on the horizontal axis. Looking at this plot is there already something we can assert about the completion dates of the work completed so far?
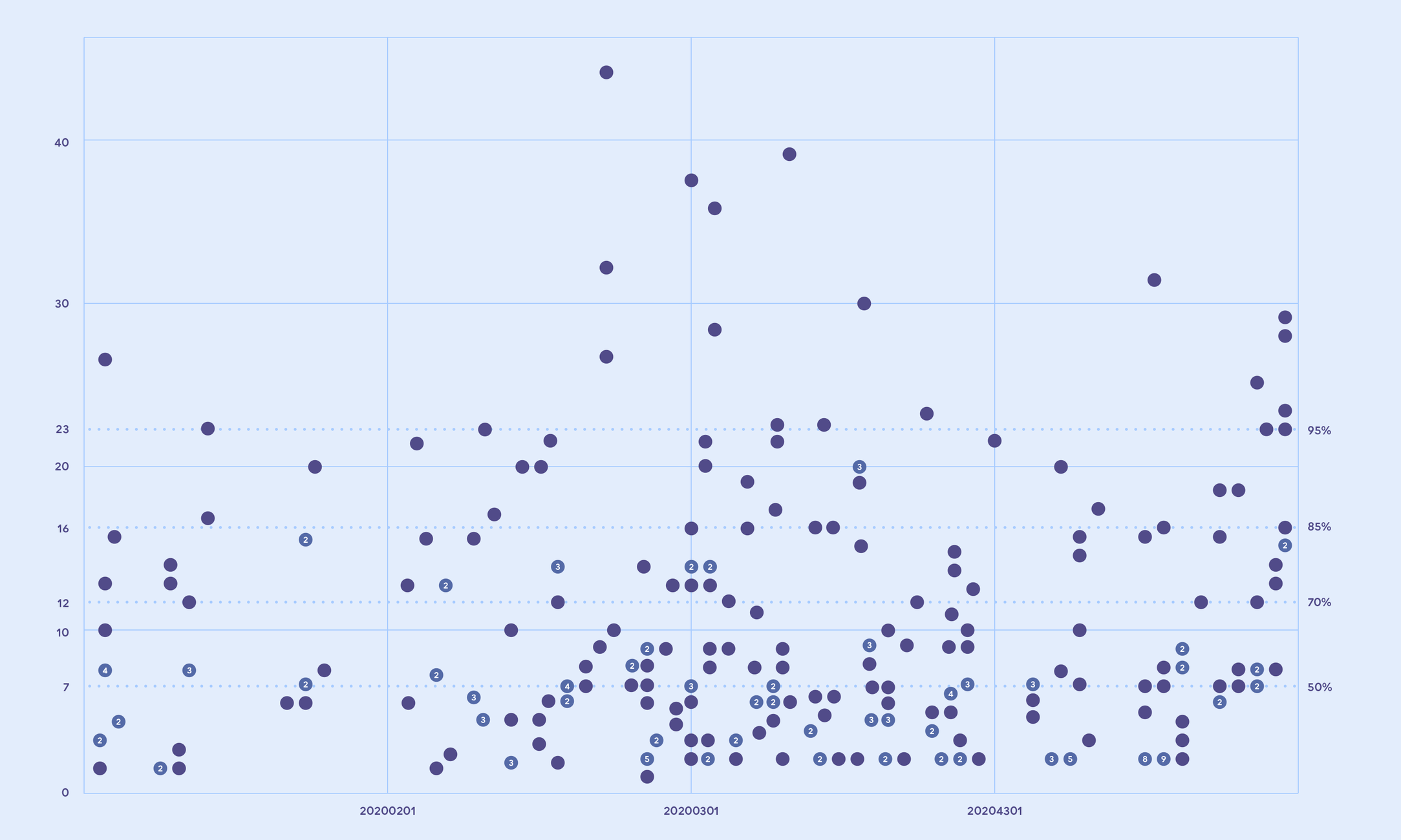
I think we can! Looking at my example plot above we can determine that nothing has taken longer than 43 days to complete so far. Notice how we can make this assertion without knowing the size of each individual piece of work that was completed.
However most items have been completed much faster. You can start dividing up the plot using percentile lines. If you would divide up the plot by counting the dots to create a ceiling where you have included 85% of the items, then we can conclude that 85% of the work took no more than 16 days to complete. You can move this percentile line up and down to get the desired certainty for your situation.
This is a great way to answer the question: when will it be done? It takes variation into account, has a certainty percentage attached to it, is free of human bias, and can be acquired in an almost automated way.
Being able to predict how much time a single work item takes is useful, but a question that is asked more often is: how much can we do in the next period of time?
As the basis for this prediction we will take the throughput of our process. Throughput is the amount of work that comes out of your project by unit of time. It’s up to you to decide what units make sense for your context. Days, weeks, sprints, stories, bugs, epics - anything goes as long as you’re consistent. Let's say for this example we are measuring the amount of stories per day. You can count how many stories get to the end of your process on a daily basis.
Using this dataset of throughput by day, we can run a Monte Carlo simulation to help us chart possible outcomes. Running a single iteration of the simulation works like this:
- Take a random throughput count from our data set
- Repeat the amount of times until we get to the target date
- Sum up the result
Repeating this little simulation of a possible outcome many times, let's say 10.000 times, we can get a better picture of which outcomes are likely to happen. Let's build a histogram with the results. The horizontal axis represents the amount of stories finished and the vertical axis how often that number came out of 10.000 simulations.
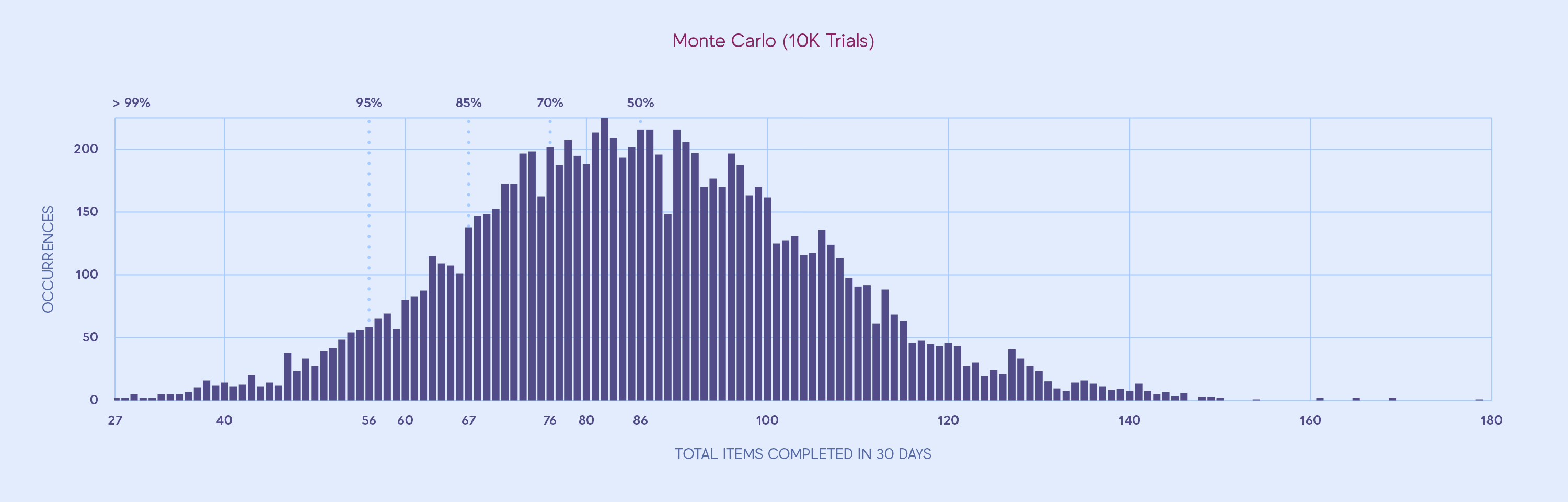
From this it's clear that some outcomes occur more often than others. It’s much more likely that the simulation ends with 80 stories done (over 200 occurrences) than with 40 stories done (~10 occurrences) or 120 stories done (under 50 occurrences). Based on this data, how likely would you think that the team can finish between 70 to 90 stories in 30 days?
Like in our first example we can use percentile lines to draw certainty intervals in our histogram. We could divide the histogram in two halves with an equal amount of outcomes on both sides and conclude there is a 50% chance that we will get that many stories done. It’s a coin flip!
Following this logic we can also divide the histogram in such a way that we get a different amount of certainty. In this example we assert that 67 stories will be completed in the next 30 days with a certainty of 85%.
Again we got to this number just by looking at our historical data, with very little effort, and without any guesses or opinions about the size of each story. Imagine how your next sprint planning improves if you would go into the meeting with these kinds of statistics prepared.
When applying the above methods to your team's data, you might be left with a desire for more precise predictions. Improving the precision of your forecast is a matter of behaving more predictably. It’s about being consistent.
Imagine making a forecast of the time it takes to ride your bike to the office. You could measure the time it takes to get there every day and use that as a basis for your forecast. Now think about how your forecast would change if you decide to take random detours in comparison to taking the fastest route. The set of possible outcomes would be much larger, and so your forecast would become less precise because it will take this uncertainty into account.
Luckily, behaving more predictably improves both teamwork as well as your forecasts. You can see this in practice when you use the historical data of a team following the Kanban practice of limiting the amount of work that is allowed to start at the same time. This drastically reduces the amount of wait time in the process. The reduced amount of variation will result in more precise forecasts. At the same time WIP limits will provide a sense of shared ownership.
In one project my team decided to start pair programming when the time it took to complete a task was in danger of violating our forecast. This was driving the variation down in our data while at the same time providing great incentives for collaboration. To use the bike example above, less variation is the equivalent of taking more predictable bike rides to the office.
Personally, I also found our historical data valuable when facilitating retrospectives with the team. The data was able to guide us to certain pain points in the process. So the application of gathering this data is certainly not limited to making forecasts - it can also be useful to identify bottlenecks and areas of improvement.
This might all sound like a lot of work but it isn't actually. Even when you are not using a digital project management system you can just start by writing down start and end dates of each chunk of work in your process and use that as an input for your forecasts. You can get started with just a simple spreadsheet.
You don't need a lot of data either. In my experience about ten items finished is already enough to get a fairly stable view of the current situation. More data isn’t even always better. It’s about selecting the relevant data for your context. If your team changes drastically you might be better off not polluting your forecast by using years of irrelevant data.
So now that you're excited to begin forecasting, some small caveats. The one thing you should really ask yourself before you get started is: why are you estimating in the first place? For a lot of teams dividing up work into manageable chunks and prioritizing that work regularly is enough. Also, really understand your desired outcome for the forecast - note that the two procedures I presented here have a very specific use case. These forecasts should not be used to judge people’s productivity or the budget needed for a project.
Now that we've gotten that out of the way, if this sounds intriguing to you at all, there are two books by Daniel Vacanti that I have found hugely informative on the topic. Actionable Agile Metrics and When Will It Be Done are available through Leanpub.
Thank you for sticking with me all the way! There is much more to say about the topic than I could cover in this blog post. At Reaktor we provide forecasting training where we go into great detail about how to apply this method. We can also help you look through the data of your teams, and help you apply this forecasting method in practice. Why not give it a try? You're welcome to email me at dirk.geurs@reaktor.com if you would like to start a conversation. The only thing you have to lose, is the time you'll gain.
Want to leverage insights from data just like this? We have a job for you, as you are. Check out Reaktor’s open positions and apply now.







