

In my previous post I argue that JavaScript is by default a low trust environment for programming, that ideas that build trust like optional typing, functional transformations, and immutability have severe trade-offs in JavaScript, and that choosing one of these ideas often means rejecting another. Despite that, JavaScript is a better environment than most popular languages for building trust, and the broader argument applies to most popular languages, typed or not.
In PureScript you get types, immutability, and functional programming “for free”– the trade-offs aren’t as steep. This is largely true of a few other languages as well, but let’s see what our discussion of fear and trust from the previous post looks like in PureScript from the same two perspectives: understanding the shape of data and changing data.
Fear and the shape of data
PureScript starts with a high level of trust in the data by default. What is the shape of our data? Whatever the type says it is.
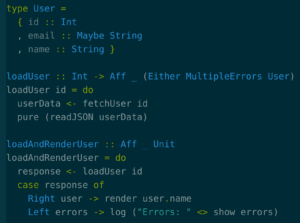
Here’s what the JavaScript example from the previous post might look like in PureScript. Like the JavaScript version, we load user data from the network and later render it. Our loadUser function takes in a user ID and returns an asynchronous effect– think of Aff like a Promise– containing either the validated user or errors. We then take this response in loadAndRenderUser and either render the user’s name, if we received a user, or log the errors if not.
The differences with JavaScript can be subtle. Everything is required to be typed within the PureScript code, so whenever you see the User type, you know it has exactly what the type says: an ID, optionally an email address, and a name. Everything is also immutable unless the type tells you otherwise, so you know this data won’t change underneath you. There are no null values. There are no any types. The value is what it says on the label. The compiler will tell you if you’re using it wrong. You can simply trust the data has the shape you expect, and will stay that way, and stop worrying about it.
What about data you get off the wire? Validation in this example happens with the call to readJSON. This takes in something with an unknown shape – a String – and attempts to turn it into a known shape – the User. It returns either the parsed user data or errors that occurred in validating the data. This is the default way of handling data that comes from outside, and this means that after this point you can trust that the data has the shape of a User. You’re not trusting the external service to provide correct data, because you validate the data as it comes in. You’re also not trusting developers to write correct types – if they write incorrect types, the validation will fail, and you will notice that.
Here’s the boilerplate for validating the data:

In most cases you don’t actually need to write any type validation logic. The compiler and library write it for you. If you have special needs, you can also write out this logic in a straightforward way manually.
The point is, as a developer you can simply trust that the data is shaped how the type says it is. What does this data look like? Does this field exist? Will changing this break the code? Read the type. Change it and let the compiler or a validation error tell you if it breaks something.
Fear and changing data
What about when the data changes? By default in PureScript all data is immutable, so instead of writing code like the mutable example from JavaScript, you might write this:
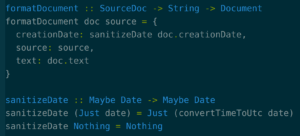
This looks a lot like the JavaScript example in the previous post using functional conventions. You take in data. You return new data. But the similarity is deceptive. This tells you much more than the JavaScript code because of the way PureScript restricts the language.
This looks just like the JavaScript code with functional conventions, but:
- It can’t mutate the data.
- It can’t modify your file system.
- It can’t launch rockets.
They’re not in the type. The type of the function is

This says you take in a SourceDoc and a String and return a Document. It can’t return anything else. It can’t return null. It can’t do other side effects like changing the data or launching rockets. This is a stupidly simple way of thinking about functions and types. A function takes in something and returns something and does nothing else.
Suppose you actually do want to mutate the data. You could write it like this:
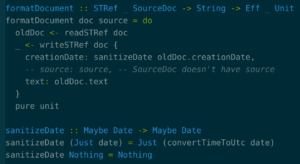
The type of our formatDocument function changed:
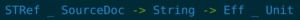
Now the function takes in a mutable reference to a document, and a string, and returns something – an effect. The effect has a type Eff _ Unit, which means that when this effect is run, it will do some side effects and return an empty value (Unit).
This is similar to the JavaScript mutation example, but with key differences. We can change the data we receive (the SourceDoc), but only that data – we still can’t change any other data in our program. We also can only change the data in ways that respect the developer’s trust. For instance, we can’t give the data a new field that is not in the type, because that would mean the type is wrong.
Suppose you actually want to launch a rocket from this function. You might write it like this:
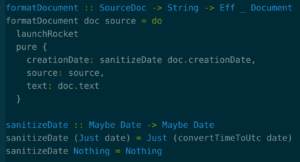
Now our function type is

Because launching a rocket is a side effect, the function needs to return an effect. The launching of rockets is explicit in the type – you can’t launch rockets without writing functions that return effects. Users of those effects have to recognize that the function returns an effect and handle it accordingly. This still doesn’t tell you what kind of effect will be performed when this is run – it could be doing many types of side effects. But it tells you clearly that the function does other things than just return a document. And the effect hasn’t actually happened yet. You might decide later that you don’t want to do the effect, and never execute it.

You could also cheat and write your document formatting mutably in JavaScript:
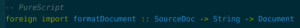
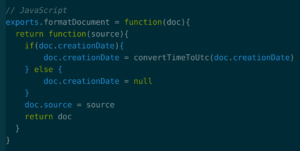
Then you’re closer to the JavaScript default, where you rely heavily on developers to maintain the shapes of your data. You’re not completely abandoning type safety – the PureScript compiler will still prevent you from changing the document within your PureScript code or using it in ways that are not supported by the type. But you’re weakening your level of trust in the code.
You probably don’t need to do this. You probably don’t want to. But you could. The code starts with the assumption of types you can trust, pure functions, and immutability, and you can selectively weaken those assumptions as needed. Or you can make them stronger, by making your types more restrictive. You have the tools to do both.
In JavaScript, by comparison, the base assumption is that you can trust very little. You build and rebuild trust into your system every day with tools like good conventions, optional typing, functional programming, and immutable data. But the bar starts low, and in JavaScript those ideas can only take you so far.
Types supporting functional programming
There’s no need to choose between types, immutability, and functional transformations. In PureScript the ideas all support each other and are pervasive in the code and ecosystem. Here are two examples.
Types and plugging functions together
Many JavaScript developers adopt tools like Ramda to do data transformations in a more functional way, with immutable defaults and useful ideas like currying and function composition. To parse and transform a set of documents received over the wire you might write something like this:
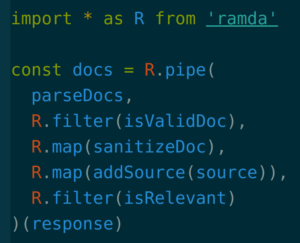
Or the same thing using the proposed `pipe` operator:

But as these pipelines get larger and the number and complexity of transformations grows it becomes harder and harder to trust that the transformations are working correctly. In theory optional typing could help with this, and you could just write the above and have TypeScript or Flow make sure the piping lines up. In simple cases the type inference for this will probably work fine and you can do that. Other times it seems to work, but it quietly wiped out your types in the middle of the pipe. Or the type inference doesn’t work at all, and you end up writing something like this, with the code logic drowned out in type annotations:
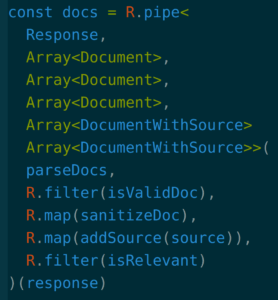
This is still a relatively simple example, but in this and especially larger examples you might also want to clean this up in a functional style. You might rewrite it like this:

Even this in simple cases type checks in TypeScript or Flow. Throw in generics right now in TypeScript and even the simplest cases fail. Flow seems to fare better, but in my experience you still run into lots of little edge cases. The TypeScript and Flow teams have been improving their handling of these cases all the time, but at some point you run into more fundamental issues around e.g. how it is possible to do type inference, while maintaining JavaScript compatibility, and avoiding making the type system brittle or complex. Ultimately when you write a lot of code like this, using function composition or lenses or other functional constructs, you have given up on the optional type system. You either don’t use types at all there, or you add verbose type coercions everywhere to make it work.
In PureScript, you just write this:
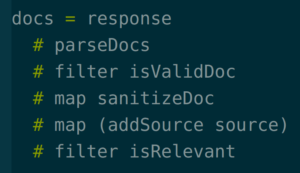
Or you rewrite it like the second JavaScript example:
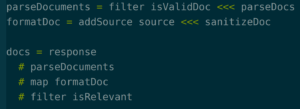
In both cases, the PureScript code looks a lot like the untyped JavaScript code, but everything is strongly typed. You can add type annotations if you like, but you don’t have to. The compiler tells you if your functions don’t line up. Most Ramda functions, even those that are difficult or impossible to type out in TypeScript or Flow, are either built in to PureScript or are trivial to write using more general tools.
More broadly, in PureScript the types help you make the piping line up for any types of transformations – data transformations, but also asynchronous network calls, or server middleware, or error handling, or config validations. When you change your code, the type system tells you whether what you wrote even makes sense with everything else that you wrote. Compared to TypeScript or Flow, PureScript is both more expressive and has better type inference. Together these mean you can write code like in a dynamic language, but keep the types. You can also use the types more easily in ways that are difficult or impossible in TypeScript or Flow, like when using function composition or lenses.
Types and immutability
PureScript uses standard JavaScript data structures under the hood, but with immutability enforced through types and the ecosystem. Libraries don’t mutate data, or if they do, it shows up in the type. There is no conflict between types and immutability – on the contrary, the types are necessary to guarantee immutability.
In JavaScript you might get immutability by adopting immutable persistent data structures, where structural sharing is used to reduce copying of data. In PureScript persistent data structures are just a performance optimization. You already have immutable data structures, which map to normal data structures in JavaScript. If you find that structural sharing would help your performance issues, you can adopt persistent data structures. Or you can write that code in JavaScript in a fast mutable style, while exposing an immutable interface to the rest of your code.
Trust and the ecosystem
Ultimately it is possible in PureScript to write the same kind of code as in JavaScript. You could even write it in JavaScript. The higher base level of trust in PureScript comes not just from the language and compiler, but also in part from strong defaults and conventions in the ecosystem.
Types are required and pervasive, and the defaults nudge you toward validating at the edges of your system. Unlike with TypeScript and Flow libraries, types live with the code that uses them, and when the types are checked, that code is checked, too. Of course, at some point many libraries wrap JavaScript libraries, and you are trusting the library developer to handle that accurately. But there are strong conventions and defaults around writing sound types, and the compiler and ecosystem help to support that. You can trust the types within your system, or if you can’t, the issue is likely in your JavaScript code or at the boundary between PureScript and JavaScript.
There’s a similar dynamic with immutability. It’s not that you couldn’t write mutable code in PureScript, or write it in JavaScript and call it from PureScript. But it’s usually much easier to do it immutably. Writing mutable code has worse ergonomics, and in some cases you would be fighting the compiler and the ecosystem. There’s a strong default of manipulating data in immutable ways, backed by the compiler. This means you can trust the data won’t change underneath you, or if it does, you see it in the types or look to the mutable JavaScript code.
Learning to code without fear
PureScript has many interesting and practical ideas, from pattern matching and ADTs to the utility of type classes to property-based testing and type level programming. But from a JavaScript perspective the biggest gains come from the simple ideas. Developers have worked hard to bring ideas like types, immutability, and functional transformations to JavaScript. They end up being a patchwork of useful tools that kind of work, if you apply them deliberately and avoid foot-guns and don’t use them too much together.
In PureScript, there’s no need to choose between these ideas. The ideas all support each other and are pervasive in the code and ecosystem.
What do pervasive strong types, immutability, and functional programming give you? A high base level of trust in the code that you write. A feeling of relative security. The confidence to refactor code freely as needed.
Programming without the fear.







