

At Aktia, utilising data and technology has been a central factor in the bank’s decision making process for almost two decades. However, analysts have found themselves using an increasing amount of their time operating data pipelines and maintaining siloed data marts with overlapping business logic. Given the scalability limitations of the existing data infrastructure, insights from new data sources – especially high volume and unstructured clickstream data – were also difficult to combine with traditional core banking data. If Aktia was going to become ever more customer driven, changes needed to happen.
The solution was to bring in Reaktor’s expertise to help build a new data platform. As a medium-sized business, using the public cloud made sense for Aktia, as they could avoid making large up-front investments in new on-premise infrastructure. In addition to utilizing managed services in the public cloud, Aktia decided to use open source where possible, as open source tools and frameworks are increasingly becoming the de-facto standard in the data space. Open source also provides a good framework for experimentation, as the cost of trying out new solutions is low. Open source also protects from unnecessary vendor-lock. And best of all, if a new feature is ever needed, Aktia can contribute it themselves.
In this post, Ville Brofeldt, Director for Data and Analytics at Aktia and our data engineer Oskari Pirttikoski tell us why – and maybe more importantly how – they created a cloud-based data lake.
A focus on privacy and security
As a bank, Aktia works with highly sensitive data, and GDPR was also on the horizon when they started this project. Beyond GDPR, the switch from on-prem to cloud also meant that additional security had to be introduced. Development followed software development best practices and the data lake uses the same authorization framework as the rest of the bank. Aktia uses dedicated connections between the on-premise and cloud environments, meaning the data is not transferred over the public internet.
At the heart of the data platform there is a pipeline that starts with sensitive data on one end and ends with loading an anonymized version of this data to a Snowflake database on the other.
The platform runs on AWS (Amazon Web Services). Apache Airflow is used for orchestration and scheduling. A staging area holds all incoming sensitive data, to which access is highly restricted. Personal data is replaced with pseudonyms to ensure that data analysts can’t see sensitive information like social security numbers, phone numbers, and so on. The end result is that normalised and masked data from diverse sources is available in one place, giving a holistic and reliable view of Aktia’s customers for analysts to work with.
Let’s get technical (a short Q&A)
Can you go into more details about the tech stack and architecture?
We use several AWS services: CloudFormation, S3, Batch, Athena, Lambda, Kinesis, EMR (Apache Spark), Aurora, DynamoDB, Sagemaker and others. As an analytical database we use Snowflake. We were also open when it came to languages – there’s Scala, Python, Go, Bash Scripts, Node.JS, Kotlin, and more.
Actually, explaining all this is going to be a bit messy, so here’s a picture instead.
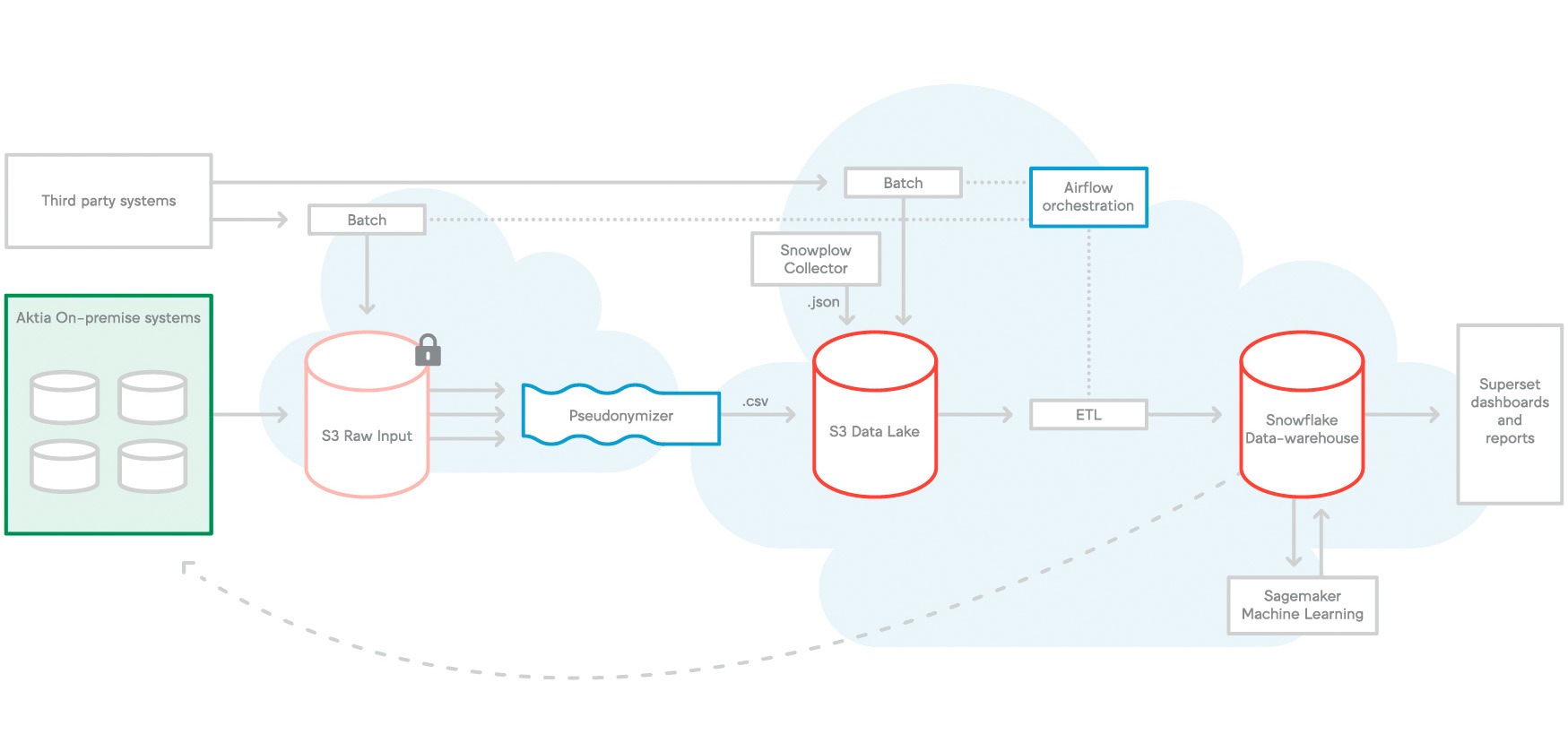
Data flows from left to right according to the arrows. Airflow orchestrates workloads.
Can you share some technical details of the system?
Sure. As one example, we implemented a simple tool called “detector” that goes through CSV files and reports which type of sensitive values it found in each column. This tool is used manually before adding new data sets to the data lake.
Here are the python regular expressions used to detect sensitive values:
The purpose here is to detect columns with sensitive values for further investigation. We don’t need to detect each and every individual value. Just most of them. So the patterns can be optimized to produce less false positives especially with corner case values. Like short phone numbers (0401234).
Even though this is not perfect, the solution turned out to be effective. Furthermore, we also use the tool to monitor that sensitive values are not found in the area where analysts are working with data.
What was most challenging from a technology point of view?
One of the challenging things was the pseudonymization and normalization of data. Phone numbers are a good example – they can be entered in numerous different formats (with international code, with spaces, with dashes) and we had to first normalize then mask it.
The purpose of normalization is to have the same masked value for one phone number no matter how it appears in the data.
A more complex example of the relationship between normalization and pseudonymisation is the Finnish personal identity code (PIC). In addition to being an identifier, it also contains the birthday and gender of the person meaning that if we use a standard method to normalize and pseudonymize, we lose this information.
So for columns containing personal identity codes, we produce two extra columns for birthday and gender. For example, here is a single row and single column CSV input file:
And here is the corresponding (pseudonymized) output file.
We also store the type of pseudonym in a separate column as some columns may contain several types of sensitive values.
Is data processed in batch or real time?
Both. Sometimes we have a need to process data in near real time (stream data), but for analytical purposes, end of day batch processing is enough.
What format do you use to store the raw data?
Raw data is stored in CSV and JSON format.
How many data sources do you collect to the lake?
We have about 20 to 25 different sources of data.
How much data do you have?
We’re at the terabyte scale (approx. 100TB). We have 1000s of tables being populated daily – the volumes are not that big but are growing.
How do you handle different kinds of data sources?
We’ve built a small framework for Docker jobs running in AWS Batch. The jobs are orchestrated with Apache Airflow. Since Docker allows you to use any tech you want, it’s flexible.
How do you avoid data duplication and redundant operations?
This wasn’t actually a problem since storage is cheap. We’ve also completely stopped using Slowly Changing Dimensions as this introduces a lot of complexity into data warehousing. We do full snapshots whenever possible since columnar storage compresses data extremely efficiently.
Did you run into any limitations with your chosen technologies?
GDPR was a big limitation. As far as I know, we were the first European bank to do full-blown production with Snowflake, which meant a lot of exploratory work. Also when working with any framework, AWS included, limitations come up – sometimes we accommodated, sometimes we worked around them.
How did you get started with this project?
At Aktia, we created an internal organization to do this work by building a new team that had the right competences to get things going. But at the same time we also knew that we needed a partner who had solved these kinds of issues before – that’s why we brought Reaktor onboard.
Is there anything you would you do differently now?
Not a lot. We did iterate a few things, and that’s natural as some of the solutions we committed to early on didn’t turn out to work as we wanted. We gave our team free hands so they could rethink what approach to use as needed. The only surprise was how long it took. We had a proof of concept early but to create the final product took about 18 months. Thinking about organizational aspects and how to bring in business users to the process is also key – you can never pay enough attention to this.
Why go to this trouble in the first place?
Like it or not, the data you use is your source of truth, even if the data is wrong. I realized this after hearing about the Amundsen project at Lyft. In order to make sure our single source of truth is as trustworthy as possible, we needed to change how we operate. Now we can get all the data from diverse sources in one place, meaning we can create a holistic – and reliable – view of the customer.
Any advice you can give to an organization thinking of doing the same?
Doing something like this is an organizational and technical change, which means both aspects need to be solved for this to work. From a tech perspective, I wouldn’t start with a massive migration project – it will just bog you down for several years, mostly without producing anything new to show for it. We decided to start by primarily integrating new systems that were not part of the legacy data warehouse. As time went by, there became a natural need to integrate to old source systems, but we did this as a natural progression.







